KMP算法小解
水背景😜
很早就想更一更题解,力扣也好,洛谷也好,写写题,记录一下思路和算法,想想就很爽😇
陆陆续续碰到过不少难题(对我而言)和马叉虫的题(不难但是思想特别好、需要一定脑回路的)
正文
KMP碰到过不少次,最早应该是在XD教学oj上做字符串的题,再后来是力扣,洛谷貌似也遇到过?当时暴力能过,看了看KMP的题解,头都大了(猪脑过载🐷),大致看了半懂就扔收藏夹吃灰辽
最近翻出来,热热还能吃琢磨看看
目前力扣是主战场,所以就贴一下那边原题罢:找到字符串中第一个匹配项的下标,本文也对标此题
虽然标的难度是简单 ,但是应该是指暴力解法,KMP方法还是需要好好想想的😪
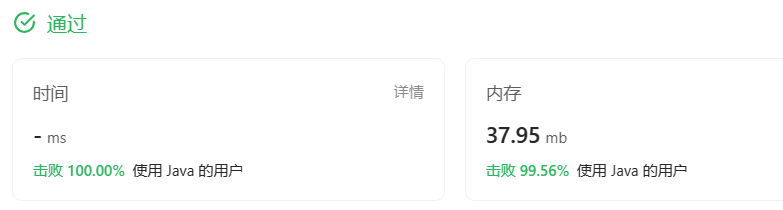
暴力解法
虽然平平无奇,还是写写分析对比一下(doge)
1 | /* |
我们的目标很简单,找到匹配下标,所以每次未匹配成功的话直接 break ,同时索引 j 都会再次回到 0 位置。
😬这样的时间复杂度是O(lenH*lenN),和KMP比起来是相当差的:
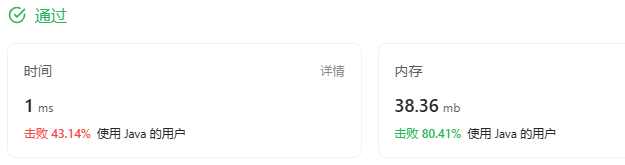
KMP解法
我们其实可以发现,在暴力解法中,虽然索引 i 表面上看起来没有动,但是实际上起比较作用的是 i + j 和 j , i 只是匹配失败后回溯到了 i + 1 位置而已。相当于:
1 | class Solution { |
回溯后的比较其实有很多是之前已经比过的,而这些地方恰恰是我们要利用的😆
Knuth-Morris-Pratt 算法,简称KMP算法,其消除了主串索引 i 的回溯,从而提高匹配效率。
在KMP算法中,i 是不能回退的,我们借助的是将 j 回退一定的步数。问题是应该回退多少步?理想情况下回退后要保证 i 左侧的字符和 j 左侧的字符能够匹配,这个时候就需要我们的前缀数组 next [] 了
求解前缀数组 next []
一点前置知识:
- 前缀: 从串首到某个位置i结束的一个子串,即s[0…i]
- 真前缀:除完整串s之外的前缀部分,相当于不看最后一个字符得到的前缀
- 后缀:从某个位置开始到串尾结束的子串,即s[i…|s|-1]
- 真后缀:同理喽,除s外的后缀,相当于不看第一个字符
- 最长公共真前后缀:顾名思义,就是真前后缀里边都有,而且最长的那条子串
比如对于串 example = “nice” 有:
前缀: n, ni, nic, nice
真前缀: n, ni, nic
后缀: e, ce, ice, nice
真后缀: e, ce, ice
最长公共真前后缀: 为空
对于KMP算法我们需要关注模式串needle的最长真前后缀
给出一个 int 数组 next [] ,其大小与needle长度相等,其元素 next[t] = k 是对于子串 s[0:t-1] 的最长公共真前后缀长度 k ,即 s[0:k-1] = s[p-k:p-1],k 也叫做失效长度,同时也就是 j 需要回退到的位置(根据最长公共真前后缀的性质,回退之后 i 和 j 左侧是完全匹配的,符合我们的要求)😮
求解思想
- 首先next[0] = -1 ,因为 0 - 1 = -1 ,已经超过最小索引无法再移动了,这相当于一个标志(所以将 -1 改为其他负数也行)
- 其次next[1] = 0 , 因为对于单个字符的子串,其真前后缀为空串,长度为 0
- 需要两个索引,p(position) 和 v(value), 分别用来记录子串右侧字符位置和子串对应的最长公共真前后缀长度。同时将 p 初始化为0,v 初始化为 next[0] 对应值
- 当 needle.charAt(p) == needle.charAt(v)时,表示最长公共真前后缀可以加长,所以next[ ++p ] = ++ v;
- 如果 needle.charAt(p) != needle.charAt(v),现在前后缀对不上,那么 v 就需要往前找更短的最长公共真前后缀,又是回溯!注意我们现在拿着的正是 next [] !!!所以不需要返回串首,直接 v = next[v],这里相当重要😎
- 综上,v 有可能回到 next[0] ,所以当 v = next[0] 时,进行 v = 0 ; next[ ++p ] = 0;
对上述思想中的4进行验证
我们假设已知 next[p] (p > 1) == k , 即 needle[0:k-1] == needle[p-k:p-1]
如果 needle[k] == needle[p] ,那么就有 needle[0:k] == needle[p-k:p], 即 next[p+1] = k + 1 ,与思想4符合
至于5的话,我没有找到/想到特别恰当的文字描述,感觉抽象地说也好理解😝
求解代码
将上述思想转化成代码实现:
1 | public int [] getNext(String needle){ |
如果将next[0] 设为 -1,代码会更简洁:😆
1 | public int [] getNext(String needle){ |
到这里基本上已经完成主要工作了,但是还不够:
实际跑的过程中,next 数组还会有一点缺陷,比如:
haystack = “aaaabcc” , needle = “aaaac”
根据之前的思路,int [] next = {-1, 0, 1, 2, 3} ;
注意:当 i 走到 4 ,j 走到 4 时 haystack.charAt(i) = ‘b’ 与 needle.charAt(j) = ‘c’ 首次匹配失败,那么 j 回退到 next[4] 即 3 , needle.charAt(j) = ‘a’ ,再次匹配失败,再次回退,结果还是’a’,还是需要回退,这样也会增加时间消耗。最理想的情况就是一下子直接回退成功,跳过中间元素重复的位置。
可以想到,因为 haystack 与 needle 匹配失败的时候有 j = next[j],
而 next[] 由 v 更新而来,我们需要跳过匹配失败的元素,所以重源头修改,当检查到元素重复我们直接跳到 next[v]:
1 | public int [] getNext(String needle){ |
修改算法之后求得的 next [] = {-1, -1, -1, -1, 3},符合预期效果😀
完整代码
哦了,next [] 数组算完了,整体代码也就完工了:
1 | class Solution { |
这次的时间复杂度是O(lenH + lenN)了,空间复杂度会略有增加😋